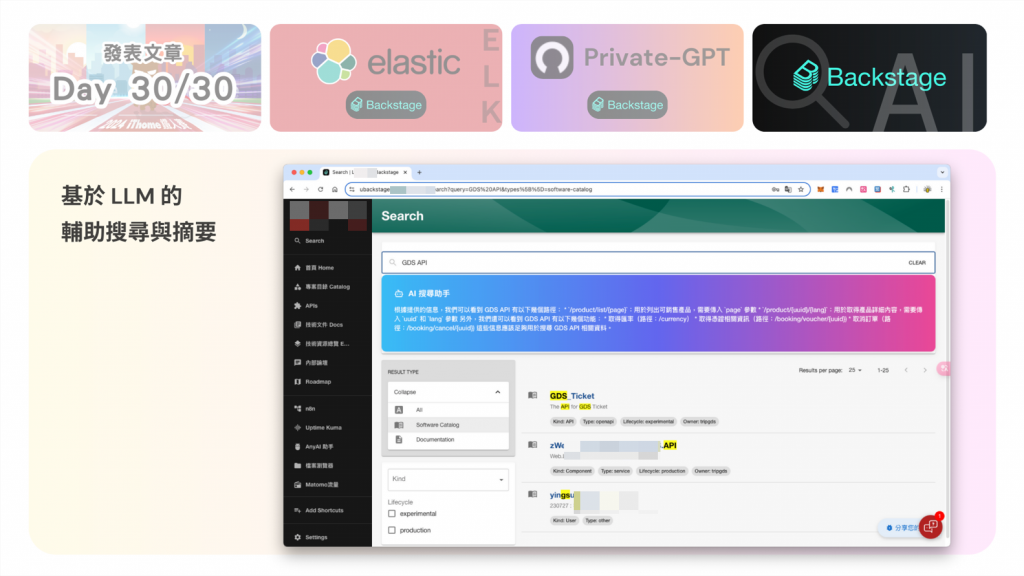
在進行鐵人賽的過程中,我主要針對 Backstage 的搜尋功能進行強化,參照前面文章的 AI 結合,剛好在完賽的今日做出了一個雛形,既然都做出來了,那就順便放上來做紀錄,先簡單描述一下功能。
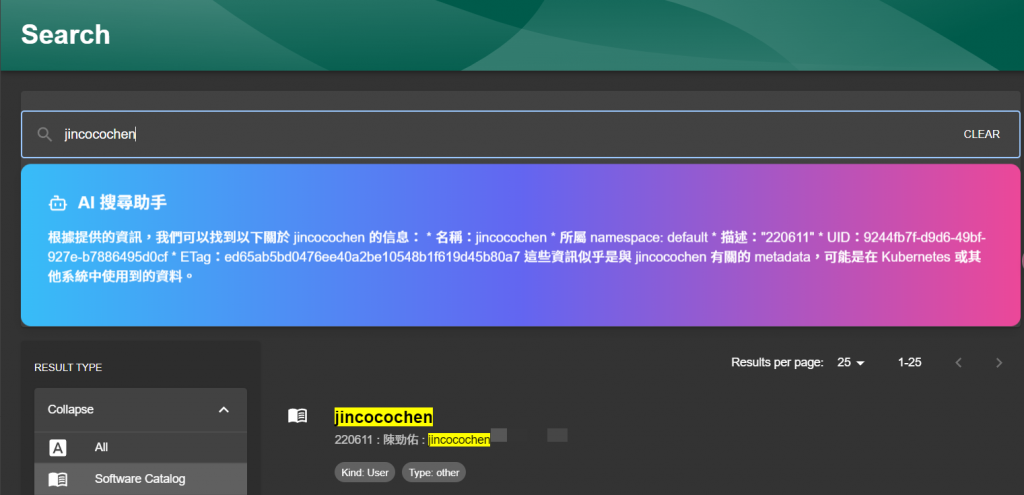
我們為 Backstage 的搜尋模組做出了兩點優化,利用 Elasticsearch 強化分詞的搜尋精準度,以及串接 Private GPT 跑本地 LLM 模型做的 AI 搜尋。除了 Backstage 基本的搜尋方法,在最上方還另外多了 AI 的智能搜尋功能,並且針對關鍵字比對 Backstage 中存在的資料,達到可以使用者可以很模糊的輸入想法來搜尋的效果。
需求與場景:
**搜尋功能整合:**當用戶在 Backstage 中搜尋時,除使用 ES 引擎搜尋 Backstage 資料,也會觸發對 Private GPT 的 RAG 搜尋,並回傳摘要結果。
**觸發機制:**當用戶輸入搜尋關鍵字,並『按下 Enter』,才會觸發後端 LLM API 開始執行。
**結果呈現:**透過 JS 進行資料串流(stream)效果的呈現,顯示搜尋結果。
**尚待解決:**目前還需要解決「Link 到檔案」的問題
Search Engines | Backstage Software Catalog and Developer Platform
參考 Backstage 官方手冊,我們可以針對預設的搜尋引擎加以改造,我們使用的是 Elasticsearch,搭配分詞器與字典的概念,能夠將一句關鍵字猜分成若干個單詞,再藉由這些單詞進行反向搜尋,速度上與精準度上都比一般的 SQL 查詢效果好。
https://github.com/infinilabs/analysis-ik
我們使用的是 ik_max_word 的分詞器,雖然它預設字典是使用簡體中文,我們可以轉換成繁體後再加入自訂義的字詞庫,讓它可以學會更多的單字,切分關鍵字時能夠讓認得。
由於使用到了分詞器,我們需要調整 Elasticsearch Plugin 的 Template,查詢時才能應用到。順帶一提在開發過程中,我使用到了 Mitmproxy 來擷取 HTTP 封包,查看 Backstage 對 Elasticsearch 送出的查詢參數,測試、調整,解決了我必須黑箱摸索結果的問題。可惜沒有在鐵人賽提到,不然相信這個概念下開發 Backstage 可以避免更多的坑。以下是我撰寫的文章參考連結:

Mitmproxy 架設 WireGuard VPN 監測手機封包
必須要以套用模板的形式,讓 Backstage 對 Elasticsearch 送出查詢時帶上分詞器的設定。
這是應用 Elasticsearch 插件與字典搭配後的搜尋效果,因為原廠的 Backstage 搜尋對中文非常不友善,常常會搜尋到不相關的字與內容,大部分其實是無法找到所需的資料的,即便資料確實存在。
如圖所例: “資訊測試人員” 被拆分成 “資訊”、”人員”、”測試”,然後再透過這幾個關鍵字去搜尋資料,再藉由找到的資料筆數與關鍵字相似度綜合評分出的排列,對比使用 SQL 的 Like 可靠非常多。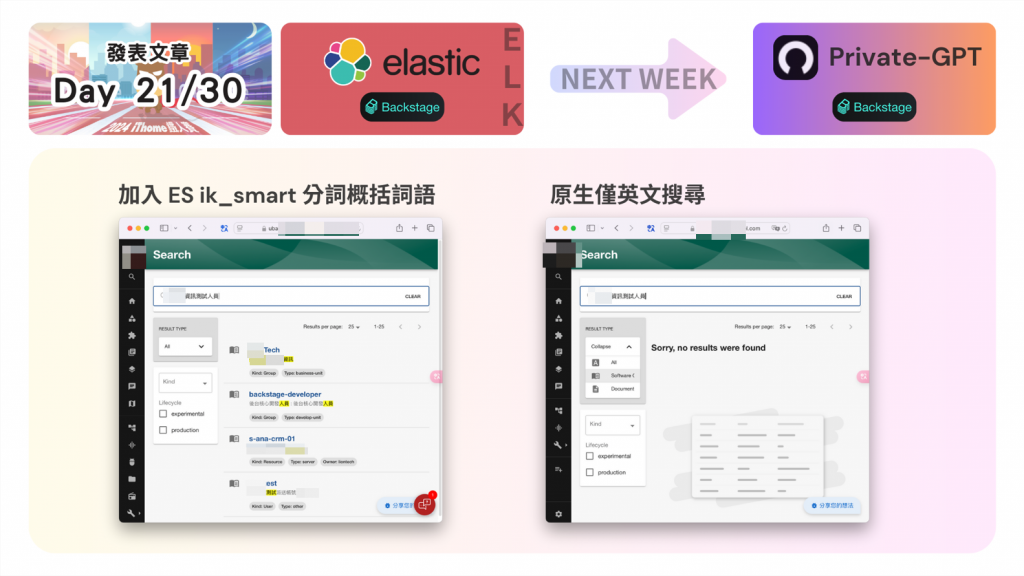
面對 AI 搜尋的部分,我們使用了 https://github.com/zylon-ai/private-gpt 來取代 Anything LLM,出色的 RAG 校調與能夠快速部署的 API 與 SDK 支援,讓我們節省了大量時間自行設計 LLM 的流程搭配,目前 PrivateGPT 預設搭配 llama 3.1 作為能夠本地運算的基礎,這是一個強大且能夠生產應用的 LLM 模型,面對中文的應對友善,測試下來有較少幻想情形,這方面也跟 PrivateGPT 的設計習習相關。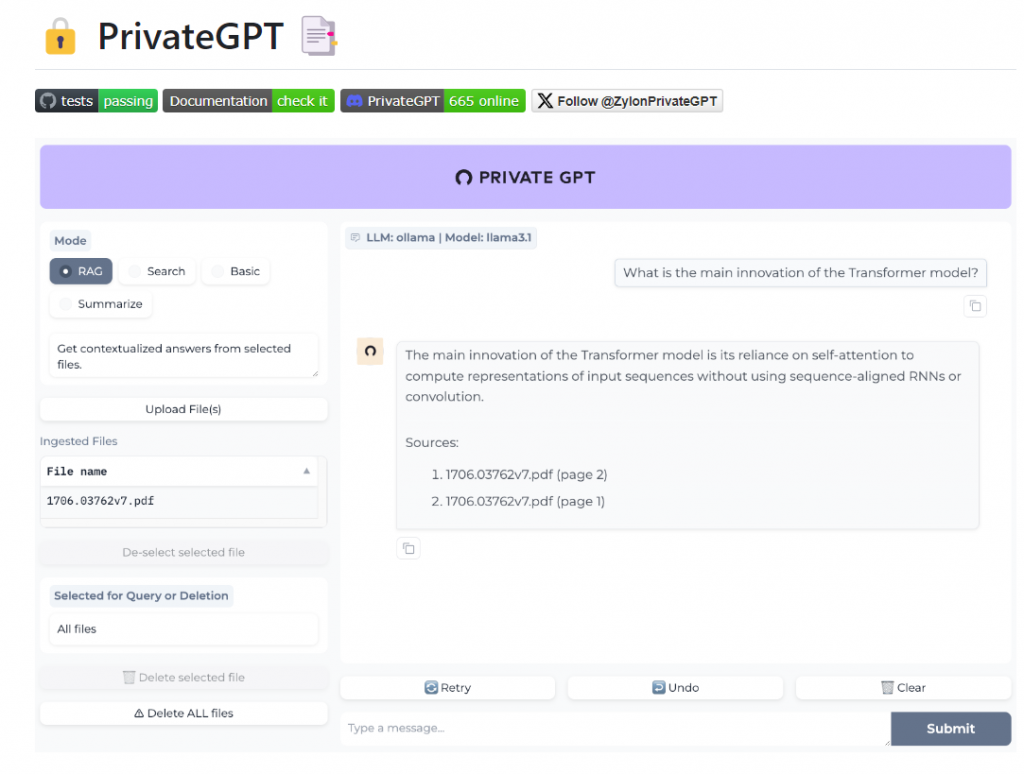
為了快速 POC 驗證,我使用了 n8n 讓我可以盡量不撰寫程式碼。將 Backstage 的實體資料從資料庫中抽取出來的 json,透過 n8n 將檔案轉換為 yaml 或是 pdf 再同步上傳到 PrivateGPT 進行 RAG,依靠 n8n 的流程大幅減少了開發時程,並且保證處理過程的品質。經過測試,PrivateGPT 面對 yaml 這類標記式語言在 RAG 時不像 Json 格式會混入大量雜質,導致輸出結果非常混亂。而 pdf 面對大型檔案,甚至是 40、50 頁的論文經過 chunks 切分檔案後,還是能輸出非常正確的結果並標出在第幾頁中的內容。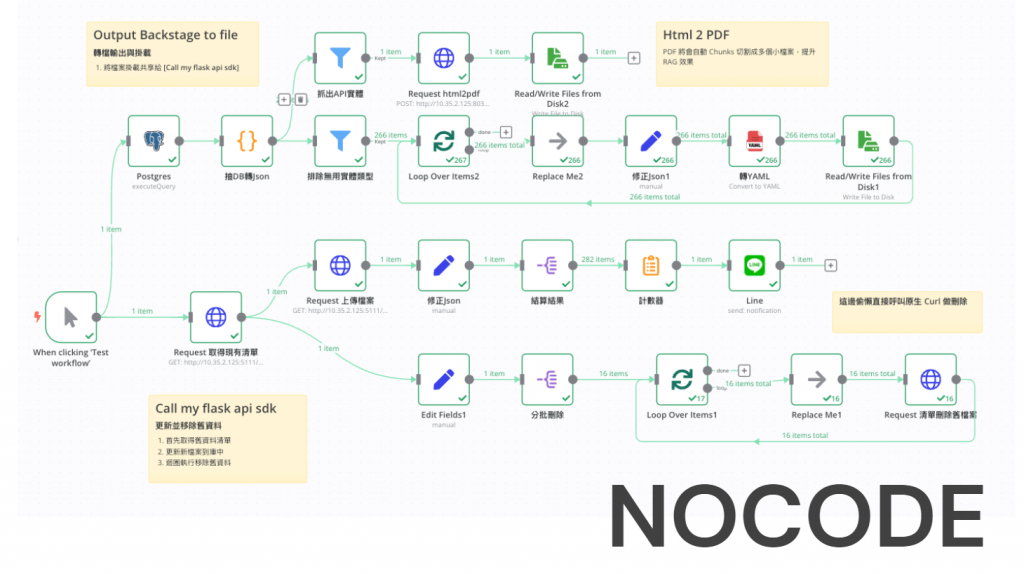
由於在開發時使用 PG Admin 時的體驗真的非常差 XD,我的 Mac Air 也跑得非常慢,於是我使用 Nocodb 可以透過網頁來檢視 Backstage 的 DB 內容,快速找到實體資料的原始格式,最後再做成插件加入到 Backstage 中。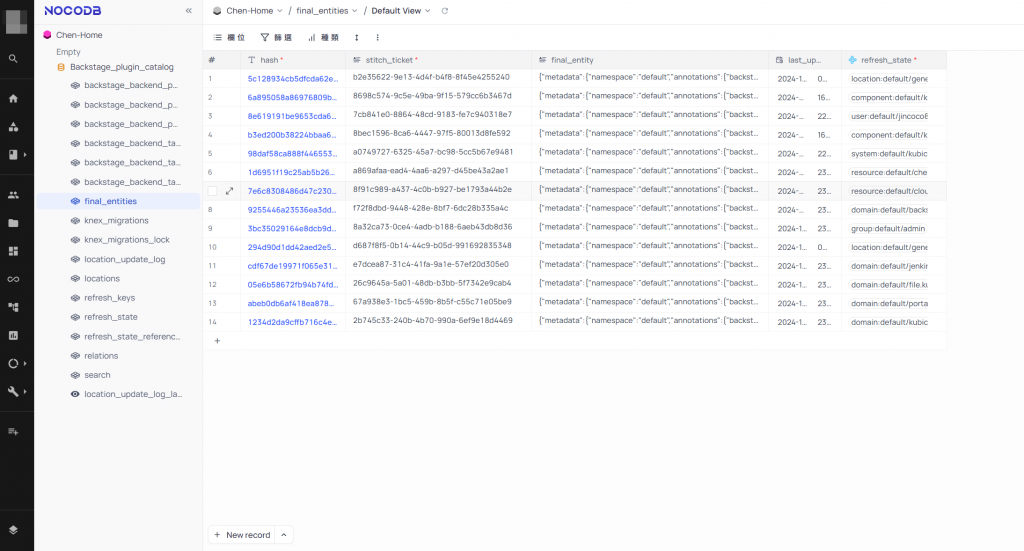
綜合起來,除了基本的關鍵字搜尋,也多了 AI 的輔助搜尋,未來搭配 AI 將搜尋到的資料做出檔案的捷徑或是下載連結,就能大幅減少了熟悉資料的時間,這概念就像 perplexity 搜尋引擎的效果。
終於到了完賽的日子,經過這30天的洗禮後,不論是寫文章的能力或是對 Backstage 的理解程度,無庸置疑的更加提升了一個境界,當然還有很大的進步空間,例如在文章上詞語的統一、或是適度加上一點幽默讓文章不會這麼無聊,每個篇幅間的規劃可以再更清晰一點等等。很高興有這次機會能參加 IT 鐵人賽,將自己的心血成果留痕在網路上,接觸 Backstage 專案的這幾個月以來真的非常有意義,這次鐵人賽就像一步步覆盤自己的成長過程,那些曾經令人焦頭爛耳的問題,如今在文章中能夠輕描淡寫,明確感覺自己又成長了。
先長枝幹、再長葉
由於自己平常有紀錄的習慣,尤其是在開發 Backstage 這類複雜架構的專案時,些紀錄讓我能夠清楚了解每一步驟的細節,並在需要時可以複習。參加鐵人賽時,這些紀錄幫我打好了「骨架」,每篇文章的基本脈絡就浮現了。就像在栽培一棵樹,先有「枝幹」,而我接下來 30 天的任務就是「長葉」,充實每片葉子的內容,將一個個獨立的節點串連成一個完整的故事。
我習慣將這些資料儲存在 Notion 上,方便我隨時複習與更新補充。先簡單地把一個知識點或議題列出來,後續在探索議題時能夠將資料先分類其中,保持一個方向的掌控。隨著深入專研每一個議題與步驟,資料的堆疊累積後就能自然形成一篇短文,再加入自己的額外細節和案例,豐富文章內容。
在自己反覆咀嚼的過程中,經常會發現自己當初開發時,未曾想到的細節或更有效率的做法,這些意外的發現也成為我寫作靈感的來源。有時候這些紀錄甚至會促使我重新思考某些開發步驟,進一步優化我的開發流程。寫作不僅僅是單純的紀錄,反而成了一個不斷反思與改進的過程。
有空檔時,我會從 Notion 的筆記上,抓一些完成度比較高的資料來寫成文章記錄,原本是想要練習一下英文,但是自從 ChatGPT 出現之後,就變成複製貼上的翻譯動作了…
心智圖,就像栽培一顆樹
在繪製「枝幹」時我最喜歡用的 Xmind 來製作心智圖,在這個視覺化的畫布上,想法或主題就像是「枝幹」,而延伸出來的細節和議題則是「樹葉」。這種搭配方式幫助我理清思緒,也讓我更容易看到結構的全貌。
繪製「枝幹」的過程就像為大腦建立一個思維基礎,隨著它的不斷延伸,逐漸深入每一個分支,將相關填入其中,雖著這張創作藍圖越發茂盛,內心的成就感就隨之增長,更驅使自己向前的動力去打造這一幅美麗的畫。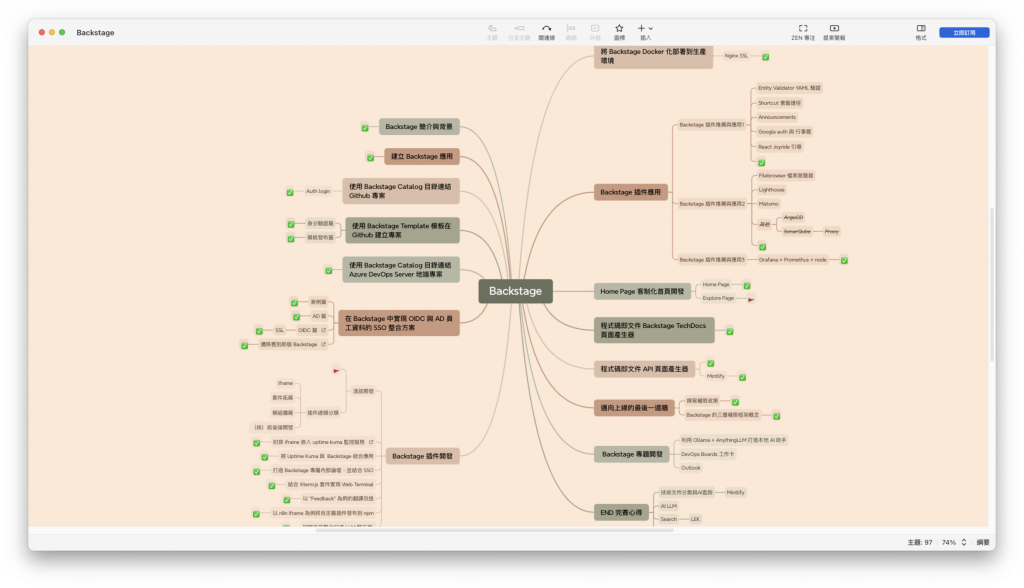
議題與議題之間,需要「軟骨」作為潤滑
在鐵人賽一天一天的文章之間,我學會了「軟骨」的概念,在這些差異明顯的議題之間,我們可以綜合兩邊的部分內容去做發想,就像潤滑液一般,為不同主題之間提供緩衝,預告讀者下一個篇章的變化,也讓自己有一個喘息的思考空間,整體文章的架構也更加流暢。
這種「軟骨」的使用,當讀者在閱讀時,期望能夠輕鬆地跟隨我的思路,從一個主題順利過渡到另一個,讓整篇文章更為自然與合理,就像在閱讀一篇故事。更重要的是,距離30天目標又更近了一步 XD (開玩笑)
目前公司內的 Backstage 處於半開放階段,首先在部門內的小組中採用,並向其他組別公布其存在與功能,同時定期更新發展進度。近期我主要專注在 IT 鐵人賽上,就暫緩了開發進度。由於目前只有我一人在維護 Backstage,能觀察和管理的範圍有限,因此這裡先針對現有的問題與未來的發展計畫進行說明。
由於 Backstage 的使用範圍目前僅限於小規模的內部應用,我們的實際使用數據還不夠全面,無法完全評估其在更大規模下的表現。未來計劃逐步擴大 Backstage 的使用範圍,最終推廣至整個 IT 部門,這將為我們提供更多實際反饋,與更多的資料可供整合。
在公司內中我們擁有多達十個左右 IT 部門,涵蓋從資料處理、系統開發到維運的各個領域,彼此的分工非常細緻。隨著各團隊獨立發展不同的系統和業務,使用的工具與技術文件管理方式也有所不同,這導致了技術文件的分散問題。為了解決「需要時找不到參考資料或負責人」的困境,我們嘗試透過 Backstage 來進行技術文件與 API 文件的整合,但效果仍有進步空間。
在先前的文章中提到,也許我們可以透過 Mintify 來打造一體式的技術文件,這個工具不僅能提供整合功能,並且還附帶了 AI 搜尋功能。我們也因此延伸出 LLM 內部知識庫的構想,儘管目前還處於概念驗證階段,但若能將這些功能整合到 Backstage 中,無疑是非常符合需求的。
Mintify 的缺點在於它依賴官方的雲端服務進行部署,並且 AI 的功能也需要透過購買服務來實現。由於公司政策不太允許將資料上傳到外部雲端,我們最終放棄了這個方案。
在這個基礎下,也許我們可以改採用開源的 Scalar,與 Mintify 概念類似除了支援 AI 的整合功能,但無論如何看起來是一個不錯的選項,AI 的部分我們能夠再另外自行開發,例如前面提到的 StagerAI 功能,在鐵人賽結束後可以再花時間研究看看。
Swagger Editor — Preview, Edit and Generate Swagger Documentation
圖片來源 / https://scalar.com/
在鐵人賽的結尾時,我發現了 Google 推出的這款線上 AI 筆記本服務 : NotebookLM,抱著好奇心試玩了一下,只能說是越過最強的 RAG 體驗,在使用短短 10 分鐘內認知到,它就是我們想做的東西,也是前面文章提到的採用 AnythingLLM 或開發一個 StagerAI 助手的功能,當我們還在慢慢校調 LLM 模型在 RAG 資料後的問答效果時,沒想到 Google 馬上就推出了一樣的東西,並且支援到 100 份文件上傳的量供 AI 讀取,看到著,突然覺得我們完全跟不上科技龍頭的腳步,它的精準度是我使用過這麼多 AI 中最精準的,當然這必須根據我們提供的資料給它使用,非常適合閱讀文件與書籍,定位與一般的問答式 AI 有所不同。
截至本文撰寫時間,AnythingLLM 尚未開放 API 的使用,以我們小組體驗後的一致認可,若未來價格合理的情況下,我們估計會直接採用它,畢竟自己開發的速度與質量完全沒辦法比擬,況且要應用在業務上對於穩定性與正確性的需求又高了。
NotebookLM | Note Taking & Research Assistant Powered by AI
Backstage 的版本更新非常頻繁,官方近期也將新版後端架構設為預設標準。遭遇這種頻繁的大幅度變動已經成為開發 Backstage 的常態。除非有重大變革或資安漏洞,我們通常不會主動升級版本,因為升級後常常會遇到 API 被棄用或名稱變更的情況,甚至導致插件衝突或功能失效。這些問題在 Backstage 從舊版過渡到新版的過程中,已經讓我們付出了許多不必要的時間成本,並且還需等待社群更新來解決相容性問題。
總歸來說 Backstage 還有很長的路要走。與市場上成熟的開源專案相比,它仍存在不少缺點,例如缺乏明確的最新版本升級指南、嚴重的歷史包袱容易導致相容性問題,以及插件和功能品質參差不齊等問題。
儘管如此,Backstage 也有其無法忽視的優勢。它提供了一個統一的開發者平台,能夠有效整合內部工具和服務,提升團隊的協作效率。Backstage 的插件化架構和模組化設計,使得它具備高度的擴展性,開發團隊可以根據自身需求定制各種功能,這對於快速變化的企業環境來說是非常有價值的。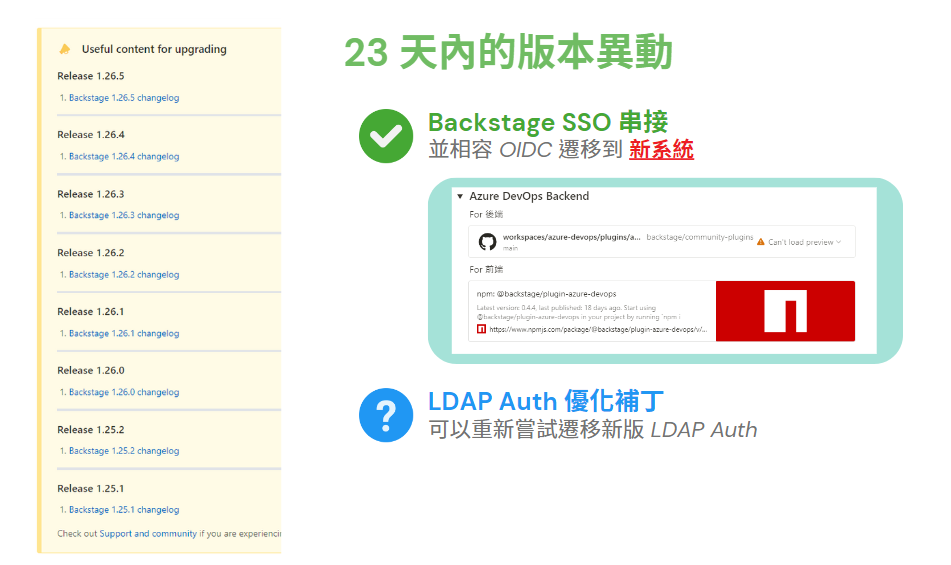
在開發過程中記錄到的情形,這些版本更動中不乏許多重大變革。
到這結束了!可喜可賀 🎉🎉🎉

